MySQL 索引
1. 什么是索引?
定义:索引是帮助存储引擎快速获取数据的一种数据结构,索引是数据的目录。
MySQL 的存储引擎有InnoDB、MyISAM、Memory等,由于MySQL 5.5之后将InnooDB设置为默认存储引擎,故本文着重讨论InnoDB存储引擎的索引(B+Tree索引)。
2. 索引分类
2.1. 四个角度分类:
- 按 数据结构 分类:B+Tree 索引、Hash 索引、Full-text 索引;
- 按 物理存储 分类:聚簇索引、二级索引;
- 按 字段特性 分类:主键索引、唯一索引、普通索引、前缀索引;
- 按 字段个数 分类:单列索引、联合索引。
2.2. B+Tree 索引、Hash 索引、Full-text 索引
- B+Tree 索引:MySQL 默认存储引擎
InnoDB支持的索引,见名知意,其底层数据结构为B+Tree,支持范围查询,是 MySQL 存储引擎采用最多的索引; - Hash 索引:底层数据结构为 Hash 表,数据存储位置经过哈希函数计算,数据与数据之间并无直接联系,无法进行范围查询,普通查询时间复杂度为
O(1); - Full-text 索引:基于相似度的查询,而不是精确数值比较。
2.3. 聚簇索引、二级索引
- 聚簇索引:又称主键索引,该索引叶子节点存储实际数据;
- 二级索引:又称辅助索引,该索引叶子节点存储的是主键值,而不是实际数据,当通过二级索引进行查询时,当查询的数据能在二级索引里查询到,不需要去聚簇索引树查询(覆盖索引),反之,则根据二级索引存储的主键值,去聚簇索引树中查询(回表)。
2.4. 主键索引、唯一索引、普通索引、前缀索引
- 主键索引:一张表最多有一个主键索引,不允许空值
- 若有主键,默认使用主键作为聚簇索引的索引键
- 若无主键,选择第一个不包含
NULL值的唯一列作为聚簇索引的索引键 - 都无的情况下,
InnoDB存储引擎就会自动生成一个隐式自增 id 列,来作为聚簇索引的索引键;
- 唯一索引:该索引的索引键存在唯一约束,建立在
UNIQUE字段上的索引,一张表可以有多个唯一索引,可以允许空值; - 普通索引:该索引的索引键无特殊约束,建立在普通字段上的索引;
- 前缀索引:对字符类型阻断的前几个字符建立的索引,而不是在整个字段上建立的索引,可以减少索引占用的存储空间,提升查询效率。
2.5. 单列索引、联合索引
- 单列索引:建立在单列上的索引;
- 联合索引:建立在多列上的索引。
3. B+Tree 索引
MySQL 的数据是持久化的,意味着数据保存在磁盘上,磁盘 I/O 速度过慢,数据库数据结构应满足:
使用尽可能少的磁盘 I/O 次数完成查询;
高效进行单一记录查询及范围查询。
3.1. B Tree、二叉树、哈希
因为涉及到范围查询,哈希表中元素无序,当在哈希表中进行范围查询,会进行全表扫描,性能过于低下!
3.1.1. 二叉查找树
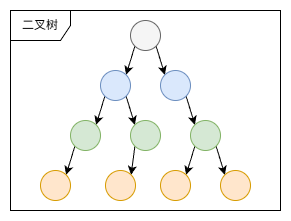
二叉查找树的特点是一个节点的左子树的所有节点小于这个节点,右子树的所有结点都大于这个节点,查找索引值target 的节点:
如果
target大于根节点,则在右子树查找;如果
target小于根节点,则在左子树查找;如果
target等于根节点,也就是找到了这个节点,返回即可。
使用二叉查找树的优缺点:
- 优点:
- 便于维护,插入新节点无需更改其他节点的位置;
- 有天然的二分结构;
- 缺点:
- 当每次插入的元素都是二叉查找树的最大元素,二叉查找树就会退化成链表,查询复杂度变为
O(1); - 二叉树高度与磁盘 I/O 问题:树的高度等于每次查询数据时磁盘 I/O 次数,随着插入元素的增多,树的高度也会变高,磁盘 I/O 次数也会变多,性能极差;
- 不支持范围查询
- 当每次插入的元素都是二叉查找树的最大元素,二叉查找树就会退化成链表,查询复杂度变为
自平衡二叉树(AVL 树)也存在虽然解决退化成链表的问题,但是在自平衡的过程中,会改动其他数据的索引,也会存在树的高度变大,磁盘 I/O 次数增多的问题;故二叉树不适合当作数据库索引。
3.1.2. B Tree
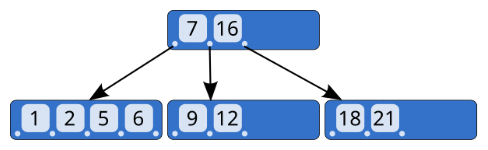
为了解决树的高度问题,前人研究出来了 B 树,它不再限制一个节点只有两个子节点,而是允许 M 个子节点(M > 2),从而降低树的高度,M 称为 B 树的阶。
上图为 4 阶 B 树,树的高度为 2,所以在查询过程中会发生 2 次磁盘 I/O 操作;但是对于范围查询,需要涉及多个、多层节点的磁盘 I/O 问题,也会导致性能下降。
3.2. B+Tree
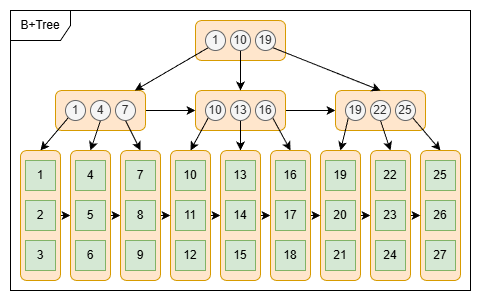
B+ 树是对 B 树做了一个升级,与 B 树差异如下:
- 叶子节点才会存放实际数据,非叶子节点只会存放索引;
- 所有索引都会在叶子节点出现,叶子节点之间形成一个有序链表;
- 非叶子节点的索引也会同时存在在叶子节点,并且是在子节点中所有索引的最大或最小;
- 非叶子节点中有多少个子节点,就有多少个索引。
3.2.1. B+Tree vs B Tree
B+Tree 只在叶子节存储数据,而 B 树的非叶子节点也要存储数据,所以 B+Tree 的翻个节点的数据量更小,在相同的磁盘 I/O 次数下,就能查询到更多的节点。
MySQL B+Tree 叶子节点采用的是双向链表连接,适合 MySQL 中常见的范围查询;
3.2.2. B+Tree vs 二叉树
对于有 N 个叶子节点的 B+Tree,其搜索复杂度为O(logmN),其中 m 表示 B+Tree 的阶数。
在实际应用中,m 的值是大于 100 的,在数据达到千万级别时,B+Tree 的高度仍维持在 34 层,一次数据查询操作只需要做 34 次磁盘 I/O 操作就能查询到目标数据。
二叉树的搜索复杂度为O(logN),检索到目标数据所经历的磁盘 I/O 次数要更多。
4. 联合索引
4.1. 最左匹配原则
前言 - 联合索引的局部有序:比如创建了一个(a,b,c)的联合索引,联合索引会先根据a字段的大小进行排序,在此基础上(a字段相等),会根据b字段大小进行排序,在对c字段进行排序,所以a全局有序,b和c局部有序。
在使用联合索引时,存在最左匹配原则,也就是按照最左有限的方式进行索引的匹配。在使用联合索引进行查询时,如果不遵循 _ 最左匹配原则 _,联合索引就会失效,无法利用到该索引快速查询的特性。
SELECT * FROM table WHERE a = 1 AND b = 2;
这条 SQL 语句能够匹配上联合索引,在 MySQL 中存在查询优化器,WHERE子句中的顺序并不重要。
SELECT * FROM table WHERE b = 2;
这条 SQL 语句并不能匹配联合索引,因为b字段在联合索引中是全局无序(只有在a字段相等的情况下才是有序)的。
能利用上索引的前提是索引键有序!
4.2. 范围查询
联合索引的范围查询,并不是联合索引中所有字段都用到了联合索引进行索引查询。
范围查询的字段可以用到联合索引,但在范围查询字段的后面的字段无法用到联合索引。
SELECT * FROM table WHERE a > 1 AND b = 1;
联合索引先按照a字段的值进行排序,所以符合a>1的索引记录是相邻的,在进行索引扫描的时候,可以定位到a>1的第一条记录,然后沿着索引向后扫描,直到不符合a>1的条件位置,所以a字段可以在联合索引的索引树中进行查询。
在符合a>1条件的耳机索引记录的范围里,b字段是无序的,并不能通过b=2的条件减少扫描的记录数量。b字段没有使用到联合索引。
SELECT * FROM table WHERE a >= 1 AND b = 1;
与上条不同的是,在a=1条件下,b字段的值是有序的,能够减少扫描的记录数,a和b字段都使用到了联合索引。
联合索引的最左匹配原则,在遇到范围查询(>、<)的时候,就会停止匹配,也就是范围查询的字段可以用到联合索引,但是在范围查询字段的后面的字段无法用到联合索引。
5. 索引失效
常见导致索引失效的情况:
- 使用左或者左右模糊匹配的时候,也就是
LIKE %xx或LIKE %xx%; - 当我们在查询条件中对索引列做了计算、函数、类型转换操作;
- 联合索引要遵循最左匹配原则,也就是按照最左优先的方式进行索引匹配,否则会导致索引失效
WHERE子句中,如果OR前的条件是索引列,后的条件列不是索引列,索引会失效;- 若索引字段区分度不大(70%),查询优化器不走索引。
MySQL 执行计划:
possible_keys:可能用到的索引;key:实际用的索引,这一项为NULL,说明没有使用索引;rows:扫描的数据行数;type:数据扫描类型。
type字段描述了找到所需数据时使用的扫描方式是什么,常见扫描类型的执行效率从低到高的顺序为:
All:全表扫描;index:全索引扫描,不需要对数据进行排序;range:索引范围扫描,一般WHERE子句中使用<、>、in、between等关键词,之间所给定范围的行,属于范围查找;尽量让 SQL 查询可以使用到range这一级别及以上的type访问方式;ref:非唯一索引扫描,或者是唯一索引的非唯一前缀,返回数据返回可能是多条,不需要扫全表,因为索引是有序的,即便有重复的,也是在一个非常小的范围内进行扫描;eq_ref:唯一索引扫描,多表联查,关联条件是a字段相等,且a是唯一索引,type就会显示eq_ref;const:结果只有一条的主键或非唯一索引扫描。
extra字段的含义:
Using filesort:当查询语句包含GROUP BY操作,而且无法利用索引完成排序操作的时候,不得不使用排序算法进行排序,甚至可能会进行文件排序,效率很低;Using temporary:使用了临时表保存中间结果,MySQL 在对查询结果排序时使用临时表,常见于排序ORDER BY和分组查询GROUP BY,效率低;Using index:所需数据只需在索引即可全部获得,不许回表,也就是使用了覆盖索引。
6. 索引优化
6.1. 前缀索引
前缀索引顾名思义是使用某个字段中字符串前几个字符建立索引,使用前缀索引是为了减少索引字段大小,可以增加一个索引页中存储的索引值,有效提高索引的查询速度。在大字符串的字段作为索引时,使用前缀索引可以帮助我们减小索引项的大小。
前缀索引有一定的局限性:
ORDER BY就无法使用前缀索引;无法把前缀索引用作覆盖索引;
6.2. 覆盖索引
覆盖索引是指 SQL 中查询的所有字段在索引 B+Tree 的叶子节点上都能找到的那些索引,从而避免回表操作。
6.3. 索引可以无节制创建吗?
索引树是动态维护,创建过多会降低插入、更新、删除的性能,应对查询较多的字段(WHERE之后的字段)建立合理的索引。
评论